Unique and Non-Unique Indexes in SQL Server
Unique Indexes:-
A unique index ensures that the indexed column contains no duplicate values. In the case of multicolumn unique indexes, the index ensures that each combination of values in the indexed column is unique.
Now, Let's explan this with an example.
We are using SQL SERVER and create table named with tblEmployeeRecord and insert some record.
In the above table tblEmployeeRecord, we have marked EmpId column, as the Primary key for this table, a UNIQUE CLUSTERED INDEX gets created on the EmpId column, with EmpId as the index key. We can verify this by executing the sp_helpindex system stored procedure as shown below and get output as shown in below.
Output:-

Since, Now we have a UNIQUE CLUSTERED INDEX on the EmpId column, any if wr try to insert duplicate the key values, will throw an error stating.
Example:-We try to insert dublicate values in tblEmployeeRecord table and errors will be occurs as following. We already inserted EmpId 1001 in tblEmployeeRecord table and we try again insert EmpId 1001 in tblEmployeeRecord table.
Ok, now we drop the Unique Clustered index on the EmpId column. For this we run the following code.
The errors will be occured as shown in below.
So, this error message proves that, SQL server internally, uses the UNIQUE index to enforce the uniqueness of values and primary key.
Go to--->> Object explorer window --->>Select Database in which we are working--->>Expand the table which one we are working--->>Expand the Indexes.
Expand keys folder in the object explorer window, and you can see a primary key constraint. Now, expand the indexes folder and you should see a unique clustered index. In the object explorer it just shows the 'CLUSTERED' word. To, confirm, this is infact an UNIQUE index, right click and select properties. The properties window, shows the UNIQUE checkbox being selected.
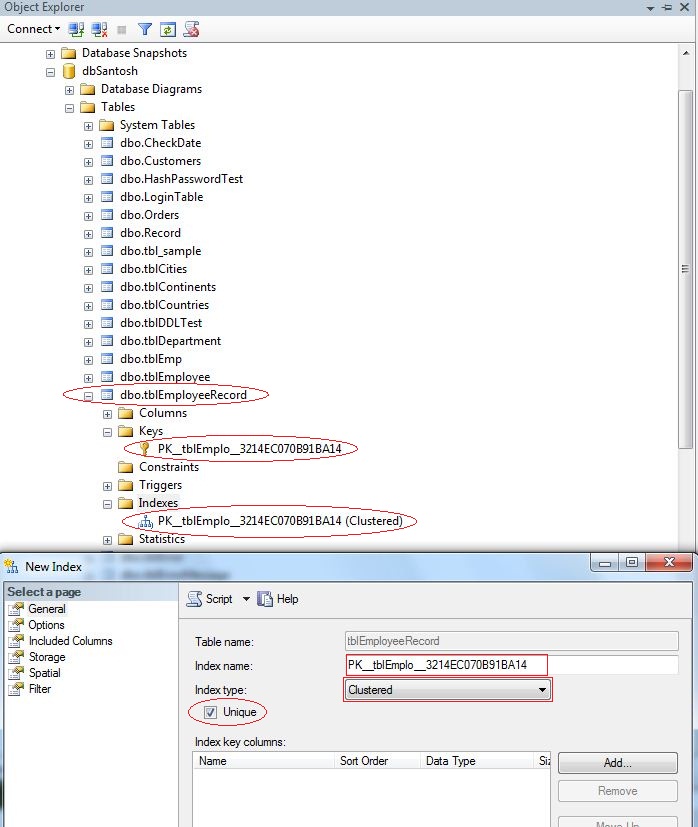
SQL Server allows us to delete this UNIQUE CLUSTERED INDEX from the object explorer. So, Right click on the index, and select DELETE and finally, click OK. Along with the UNIQUE index, the primary key constraint is also deleted.
Now, we can insert duplicate values for the EmpId column. The rows should be accepted, without any primary key violation error.
Creating a UNIQUE NON CLUSTERED index on the Name and Salry columns.
This unique non clustered index, ensures that no 2 entires in the index has the same Name and Salary, We have learnt that, a Unique Constraint, can be used to enforce the uniqueness of values, across one or more columns. There are no major differences between a unique constraint and a unique index.
In fact, when you add a unique constraint, a unique index created automatically in behind the scenes. To prove this, let's add a unique constraint on the Address column of the tblEmployeeRecord table.
At this point, we expect a unique constraint to be created. Refresh and Expand the constraints folder in the object explorer window. The constraint is not present in this folder. Now, refresh and expand the 'indexes' folder. In the indexes folder, you will see a UNIQUE NONCLUSTERED index with name UQ_tblEmployeeRecord_Address. Also, We can execute following code for see UNIQUE NONCLUSTERED index.

NOTE:-
A unique index ensures that the indexed column contains no duplicate values. In the case of multicolumn unique indexes, the index ensures that each combination of values in the indexed column is unique.
Now, Let's explan this with an example.
We are using SQL SERVER and create table named with tblEmployeeRecord and insert some record.
CREATE TABLE tblEmployeeRecord ( EmpId int Primary Key, Name nvarchar(10), Email nvarchar(100), Department varchar(30), Salary int, Gender nvarchar(20), Address nvarchar(200) ) ---------Insert some records---------- INSERT INTO tblEmployeeRecord VALUES(1001,'Santosh kumar singh','sk@gmail.com','IT',1200,'Male','A-34') INSERT INTO tblEmployeeRecord VALUES(1002,'Madan sharma','m@gmail.com','CSE',1700,'Male','D-30') INSERT INTO tblEmployeeRecord VALUES(1003,'Manjari Tripathi','mt@gmail.com','ECE',1100,'Female','H-210')
In the above table tblEmployeeRecord, we have marked EmpId column, as the Primary key for this table, a UNIQUE CLUSTERED INDEX gets created on the EmpId column, with EmpId as the index key. We can verify this by executing the sp_helpindex system stored procedure as shown below and get output as shown in below.
Execute sp_helpindex tblEmployeeRecord
Since, Now we have a UNIQUE CLUSTERED INDEX on the EmpId column, any if wr try to insert duplicate the key values, will throw an error stating.
Example:-We try to insert dublicate values in tblEmployeeRecord table and errors will be occurs as following. We already inserted EmpId 1001 in tblEmployeeRecord table and we try again insert EmpId 1001 in tblEmployeeRecord table.
INSERT INTO tblEmployeeRecord VALUES(1001,'Er. Gagan','eg@gmail.com','ECE',1000,'Female','R-30')
Violation of PRIMARY KEY constraint 'PK__tblEmplo__3214EC070B91BA14'. Cannot insert duplicate key in object 'dbo.tblEmployeeRecord'.
Ok, now we drop the Unique Clustered index on the EmpId column. For this we run the following code.
Drop index tblEmployee.PK__tblEmplo__3214EC070B91BA14
The errors will be occured as shown in below.
Msg 3701, Level 11, State 7, Line 1
Cannot drop the index 'tblEmployee.PK__tblEmplo__3214EC070B91BA14', because it does not exist or you do not have permission.
Cannot drop the index 'tblEmployee.PK__tblEmplo__3214EC070B91BA14', because it does not exist or you do not have permission.
So, this error message proves that, SQL server internally, uses the UNIQUE index to enforce the uniqueness of values and primary key.
Go to--->> Object explorer window --->>Select Database in which we are working--->>Expand the table which one we are working--->>Expand the Indexes.
Expand keys folder in the object explorer window, and you can see a primary key constraint. Now, expand the indexes folder and you should see a unique clustered index. In the object explorer it just shows the 'CLUSTERED' word. To, confirm, this is infact an UNIQUE index, right click and select properties. The properties window, shows the UNIQUE checkbox being selected.
SQL Server allows us to delete this UNIQUE CLUSTERED INDEX from the object explorer. So, Right click on the index, and select DELETE and finally, click OK. Along with the UNIQUE index, the primary key constraint is also deleted.
Now, we can insert duplicate values for the EmpId column. The rows should be accepted, without any primary key violation error.
INSERT INTO tblEmployeeRecord VALUES(1001,'Santosh kumar singh','sk@gmail.com','IT',1200,'Male','A-34') INSERT INTO tblEmployeeRecord VALUES(1001,'Er. Gagan','eg@gmail.com','ECE',1000,'Female','R-30')
- The UNIQUE index is used to enforce the uniqueness of values and primary key constraint.
- UNIQUENESS is a property of an Index, and both CLUSTERED and NON-CLUSTERED indexes can be UNIQUE.
Creating a UNIQUE NON CLUSTERED index on the Name and Salry columns.
CREATE UNIQUE NONCLUSTERED INDEX tblEmployeeRecord_Name_Salary ON tblEmployeeRecord(Name, Salary)
This unique non clustered index, ensures that no 2 entires in the index has the same Name and Salary, We have learnt that, a Unique Constraint, can be used to enforce the uniqueness of values, across one or more columns. There are no major differences between a unique constraint and a unique index.
In fact, when you add a unique constraint, a unique index created automatically in behind the scenes. To prove this, let's add a unique constraint on the Address column of the tblEmployeeRecord table.
ALTER TABLE tblEmployeeRecord ADD CONSTRAINT UQ_tblEmployeeRecord_Address UNIQUE NONCLUSTERED (Address)
At this point, we expect a unique constraint to be created. Refresh and Expand the constraints folder in the object explorer window. The constraint is not present in this folder. Now, refresh and expand the 'indexes' folder. In the indexes folder, you will see a UNIQUE NONCLUSTERED index with name UQ_tblEmployeeRecord_Address. Also, We can execute following code for see UNIQUE NONCLUSTERED index.
EXECUTE sp_helpconstraint tblEmployeeRecord
NOTE:-
- By default, a PRIMARY KEY constraint, creates a unique clustered index, where as a UNIQUE constraint creates a unique nonclustered index. These defaults can be changed if you wish to.
- A UNIQUE constraint or a UNIQUE index cannot be created on an existing table, if the table contains duplicate values in the key columns. Obviously, to solve this,remove the key columns from the index definition or delete or update the duplicate values.
- By default, duplicate values are not allowed on key columns, when you have a unique index or constraint. For, example, if I try to insert 10 rows, out of which 5 rows contain duplicates, then all the 10 rows are rejected. However, if I want only the 5 duplicate rows to be rejected and accept the non-duplicate 5 rows, then I can use IGNORE_DUP_KEY option. An example of using IGNORE_DUP_KEY option is shown below.
CREATE UNIQUE INDEX UQ_tblEmployeeRecord_Address ON tblEmployeeRecord(Address) WITH IGNORE_DUP_KEY